|


其中:
1、
VGG 网络以及从 2012 年以来的 AlexNet 都遵循现在的基本卷积网络的原型布局:一系列卷积层、最大池化层和激活层,最后还有一些全连接的分类层。
2、
ResNet 的作者将这些问题归结成了一个单一的假设:直接映射是难以学习的。而且他们提出了一种修正方法:不再学习从 x 到 H(x) 的基本映射关系,而是学习这两者之间的差异,也就是「残差(residual)」。然后,为了计算 H(x),我们只需要将这个残差加到输入上即可。
假设残差为 F(x)=H(x)-x,那么现在我们的网络不会直接学习 H(x) 了,而是学习 F(x)+x。
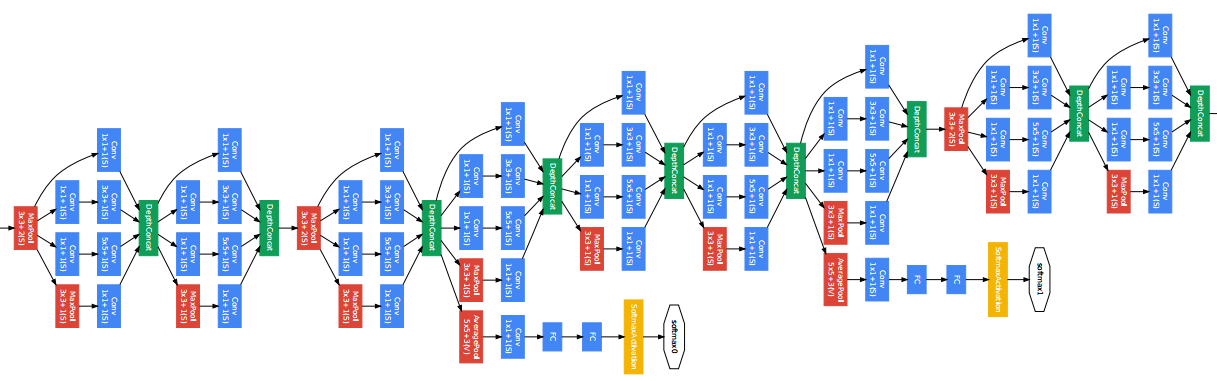
这就带来了你可能已经见过的著名 ResNet(残差网络)模块
3、Inception 的作者使用了 1×1 卷积来「过滤」输出的深度。一个 1×1 卷积一次仅查看一个值,但在多个通道上,它可以提取空间信息并将其压缩到更低的维度。比如,使用 20 个 1×1 过滤器,一个大小为 64×64×100(具有 100 个特征映射)的输入可以被压缩到 64×64×20。通过减少输入映射的数量,Inception 可以将不同的层变换并行地堆叠到一起,从而得到既深又宽(很多并行操作)的网络。
4、Xception 更进一步。不再只是将输入数据分割成几个压缩的数据块,而是为每个输出通道单独映射空间相关性,然后再执行 1×1 的深度方面的卷积来获取跨通道的相关性。从而获得较好的效率。并且这个架构已经在通过 MobileNet 助力谷歌的移动视觉应用了。
最后,
迁移学习是一种机器学习技术,即我们可以将一个领域的知识(比如 ImageNet)应用到目标领域,从而可以极大减少所需要的数据点。在实践中,这通常涉及到使用来自 ResNet、Inception 等的预训练的权重初始化模型,然后要么将其用作特征提取器,要么就在一个新数据集上对最后几层进行微调。使用迁移学习,这些模型可以在任何我们想要执行的相关任务上得到重新利用,从自动驾驶汽车的目标检测到为视频片段生成描述。
深度学习需要大量数据才能训练处一个较好的模型。但是,有时候我们很难获取大量数据,因为得到足够大样本量的特定领域的数据集并不是那么容易,这是否就意味着我们不能使用上深度学习这一黑科技啦?我很高兴的告诉大家,事实并非如此。迁移学习就可以帮助我们使用上深度学习这一高大上的技术。
何为迁移学习?迁移学习是指使用一个预训练的网络:比如 VGG16 。VGG16 是基于大量真实图像的 ImageNet 图像库预训练的网络。我们将学习的 VGG16 的权重迁移(transfer)到自己的卷积神经网络上作为网络的初始权重,然后微调(fine-tune)这些预训练的通用网络使它们能够识别出人的activities图像,从而提高对HAR的预测效果。
5、直接使用vgg来预测
这里我使用了一些小技巧。
from keras.applications.resnet50
import ResNet50
from keras.preprocessing
import image
from keras.applications.resnet50
import preprocess_input, decode_predictions
import numpy as np
from keras.utils.data_utils
import get_file
model
= ResNet50(weights
=
'imagenet')
path
=
'1.jpg'
img_path
= get_file(path,origin
=
'http://pic.qiantucdn.com/58pic/26/23/18/58c959d01a57d_1024.jpg')
print(img_path)
img
= image.load_img(img_path, target_size
=(
224,
224))
x
= image.img_to_array(img)
x
= np.expand_dims(x, axis
=
0)
x
= preprocess_input(x)
preds
= model.predict(x)
print(
'Predicted:', decode_predictions(preds, top
=
3)[
0])
# Predicted: [(u'n02504013', u'Indian_elephant', 0.82658225), (u'n01871265', u'tusker', 0.1122357), (u'n02504458', u'African_elephant', 0.061040461)]
6、迁移学习
为了对迁移学习产生一个直观的认识,不妨拿老师与学生之间的关系做类比。
一位老师通常在ta所教授的领域有着多年丰富的经验,在这些积累的基础上,老师们能够在课堂上教授给学生们该领域最简明扼要的内容。这个过程可以看做是老手与新手之间的“信息迁移”。
这个过程在神经网络中也适用。
我们知道,神经网络需要用数据来训练,它从数据中获得信息,进而把它们转换成相应的权重。这些权重能够被提取出来,迁移到其他的神经网络中,我们“迁移”了这些学来的特征,就不需要从零开始训练一个神经网络了 。
简单来说,预训练模型(pre-trained model)是前人为了解决类似问题所创造出来的模型。你在解决问题的时候,不用从零开始训练一个新模型,可以从在类似问题中训练过的模型入手。
场景一:数据集小,数据相似度高(与pre-trained model的训练数据相比而言)
在这种情况下,因为数据与预训练模型的训练数据相似度很高,因此我们不需要重新训练模型。我们只需要将输出层改制成符合问题情境下的结构就好。
我们使用预处理模型作为模式提取器。
比如说我们使用在ImageNet上训练的模型来辨认一组新照片中的小猫小狗。在这里,需要被辨认的图片与ImageNet库中的图片类似,但是我们的输出结果中只需要两项——猫或者狗。
在这个例子中,我们需要做的就是把dense layer和最终softmax layer的输出从1000个类别改为2个类别。
场景二:数据集小,数据相似度不高
在这种情况下,我们可以冻结预训练模型中的前k个层中的权重,然后重新训练后面的n-k个层,当然最后一层也需要根据相应的输出格式来进行修改。
因为数据的相似度不高,重新训练的过程就变得非常关键。而新数据集大小的不足,则是通过冻结预训练模型的前k层进行弥补。
场景三:数据集大,数据相似度不高
在这种情况下,因为我们有一个很大的数据集,所以神经网络的训练过程将会比较有效率。然而,因为实际数据与预训练模型的训练数据之间存在很大差异,采用预训练模型将不会是一种高效的方式。
因此最好的方法还是将预处理模型中的权重全都初始化后在新数据集的基础上重头开始训练。
场景四:数据集大,数据相似度高
这就是最理想的情况,采用预训练模型会变得非常高效。最好的运用方式是保持模型原有的结构和初始权重不变,随后在新数据集的基础上重新训练。
去模型训练要消耗更多资源,也是 我目前的设备所不能支持的。所以在这段时间里面,主要 做的就是迁移学习,这一点是新的课题。
7、使用vgg16作为预训练的模型结构,并把它应用到手写数字识别上
对于imagenet来说,mnist显而易见属于小数据,所以是1/2类的。分别来看一下
冻结冻结部分参数
import numpy as np
from keras.datasets
import mnist
import gc
from keras.models
import Sequential, Model
from keras.layers
import Input, Dense, Dropout, Flatten
from keras.layers.convolutional
import Conv2D, MaxPooling2D
from keras.applications.vgg16
import VGG16
from keras.optimizers
import SGD
import cv2
import h5py as h5py
import numpy as np
def tran_y(y)
:
y_ohe
= np.zeros(
10)
y_ohe[y]
=
1
return y_ohe
# 如果硬件配置较高,比如主机具备32GB以上内存,GPU具备8GB以上显存,可以适当增大这个值。VGG要求至少48像素
ishape
=
48
(X_train, y_train), (X_test, y_test)
= mnist.load_data()
X_train
= [cv2.cvtColor(cv2.resize(i, (ishape, ishape)), cv2.COLOR_GRAY2BGR)
for i
in X_train]
X_train
= np.concatenate([arr[np.newaxis]
for arr
in X_train]).astype(
'float32')
X_train
/=
255.
0
X_test
= [cv2.cvtColor(cv2.resize(i, (ishape, ishape)), cv2.COLOR_GRAY2BGR)
for i
in X_test]
X_test
= np.concatenate([arr[np.newaxis]
for arr
in X_test]).astype(
'float32')
X_test
/=
255.
0
y_train_ohe
= np.
array([tran_y(y_train)
for i
in
range(
len(y_train))])
y_test_ohe
= np.
array([tran_y(y_test)
for i
in
range(
len(y_test))])
y_train_ohe
= y_train_ohe.astype(
'float32')
y_test_ohe
= y_test_ohe.astype(
'float32')
model_vgg
= VGG16(include_top
=
False, weights
=
'imagenet', input_shape
= (ishape, ishape,
3))
#for i, layer in enumerate(model_vgg.layers):
# if i<20:
for layer
in model_vgg.layers
:
layer.trainable
=
False
model
= Flatten()(model_vgg.output)
model
= Dense(
4096, activation
=
'relu', name
=
'fc1')(model)
model
= Dense(
4096, activation
=
'relu', name
=
'fc2')(model)
model
= Dropout(
0.
5)(model)
model
= Dense(
10, activation
=
'softmax', name
=
'prediction')(model)
model_vgg_mnist_pretrain
= Model(model_vgg.
input, model, name
=
'vgg16_pretrain')
model_vgg_mnist_pretrain.summary()
sgd
= SGD(lr
=
0.
05, decay
=
1e
-
5)
model_vgg_mnist_pretrain.
compile(loss
=
'categorical_crossentropy', optimizer
= sgd, metrics
= [
'accuracy'])
model_vgg_mnist_pretrain.fit(X_train, y_train_ohe, validation_data
= (X_test, y_test_ohe), epochs
=
10, batch_size
=
64)
#del(model_vgg_mnist_pretrain, model_vgg, model)
for i
in
range(
100)
:
gc.collect()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) (None, 48, 48, 3) 0
_________________________________________________________________
block1_conv1 (Conv2D) (None, 48, 48, 64) 1792
_________________________________________________________________
block1_conv2 (Conv2D) (None, 48, 48, 64) 36928
_________________________________________________________________
block1_pool (MaxPooling2D) (None, 24, 24, 64) 0
_________________________________________________________________
block2_conv1 (Conv2D) (None, 24, 24, 128) 73856
_________________________________________________________________
block2_conv2 (Conv2D) (None, 24, 24, 128) 147584
_________________________________________________________________
block2_pool (MaxPooling2D) (None, 12, 12, 128) 0
_________________________________________________________________
block3_conv1 (Conv2D) (None, 12, 12, 256) 295168
_________________________________________________________________
block3_conv2 (Conv2D) (None, 12, 12, 256) 590080
_________________________________________________________________
block3_conv3 (Conv2D) (None, 12, 12, 256) 590080
_________________________________________________________________
block3_pool (MaxPooling2D) (None, 6, 6, 256) 0
_________________________________________________________________
block4_conv1 (Conv2D) (None, 6, 6, 512) 1180160
_________________________________________________________________
block4_conv2 (Conv2D) (None, 6, 6, 512) 2359808
_________________________________________________________________
block4_conv3 (Conv2D) (None, 6, 6, 512) 2359808
_________________________________________________________________
block4_pool (MaxPooling2D) (None, 3, 3, 512) 0
_________________________________________________________________
block5_conv1 (Conv2D) (None, 3, 3, 512) 2359808
_________________________________________________________________
block5_conv2 (Conv2D) (None, 3, 3, 512) 2359808
_________________________________________________________________
block5_conv3 (Conv2D) (None, 3, 3, 512) 2359808
_________________________________________________________________
block5_pool (MaxPooling2D) (None, 1, 1, 512) 0
_________________________________________________________________
flatten_2 (Flatten) (None, 512) 0
_________________________________________________________________
fc1 (Dense) (None, 4096) 2101248
_________________________________________________________________
fc2 (Dense) (None, 4096) 16781312
_________________________________________________________________
dropout_2 (Dropout) (None, 4096) 0
_________________________________________________________________
prediction (Dense) (None, 10) 40970
=================================================================
Total params: 33,638,218
Trainable params: 18,923,530
Non-trainable params: 14,714,688
_________________________________________________________________
Train on 60000 samples, validate on 10000 samples
Epoch 1/10
1536/60000 [..............................] - ETA: 1:11 - loss: 1.9721 - acc: 0.3151
60000/60000 [==============================] - 67s 1ms/step - loss: 0.5427 - acc: 0.8236 - val_loss: 0.2638 - val_acc: 0.9082
Epoch 2/10
6592/60000 [==>...........................] - ETA: 52s - loss: 0.3103 - acc: 0.8959
60000/60000 [==============================] - 67s 1ms/step - loss: 0.2440 - acc: 0.9198 - val_loss: 0.1813 - val_acc: 0.9420
Epoch 3/10
8512/60000 [===>..........................] - ETA: 51s - loss: 0.1815 - acc: 0.9424
60000/60000 [==============================] - 67s 1ms/step - loss: 0.1864 - acc: 0.9396 - val_loss: 0.4216 - val_acc: 0.8529
Epoch 4/10
9152/60000 [===>..........................] - ETA: 50s - loss: 0.1669 - acc: 0.9453
60000/60000 [==============================] - 67s 1ms/step - loss: 0.1599 - acc: 0.9491 - val_loss: 0.2004 - val_acc: 0.9342
Epoch 5/10
9536/60000 [===>..........................] - ETA: 50s - loss: 0.1396 - acc: 0.9556
60000/60000 [==============================] - 67s 1ms/step - loss: 0.1402 - acc: 0.9552 - val_loss: 0.1723 - val_acc: 0.9443
Epoch 6/10
9536/60000 [===>..........................] - ETA: 50s - loss: 0.1302 - acc: 0.9560
60000/60000 [==============================] - 67s 1ms/step - loss: 0.1251 - acc: 0.9591 - val_loss: 0.2076 - val_acc: 0.9306
Epoch 7/10
9536/60000 [===>..........................] - ETA: 50s - loss: 0.1412 - acc: 0.9523
60000/60000 [==============================] - 67s 1ms/step - loss: 0.1237 - acc: 0.9596 - val_loss: 0.1176 - val_acc: 0.9607
Epoch 8/10
9472/60000 [===>..........................] - ETA: 50s - loss: 0.1133 - acc: 0.9637
60000/60000 [==============================] - 68s 1ms/step - loss: 0.1085 - acc: 0.9651 - val_loss: 0.1021 - val_acc: 0.9669
Epoch 9/10
9472/60000 [===>..........................] - ETA: 50s - loss: 0.1051 - acc: 0.9670
60000/60000 [==============================] - 67s 1ms/step - loss: 0.1041 - acc: 0.9662 - val_loss: 0.1091 - val_acc: 0.9652
Epoch 10/10
9600/60000 [===>..........................] - ETA: 49s - loss: 0.1140 - acc: 0.9633
60000/60000 [==============================] - 67s 1ms/step - loss: 0.0996 - acc: 0.9671 - val_loss: 0.1198 - val_acc: 0.9607
Test loss: 0.1198318742185831
Test accuracy: 0.9607
某种程度上,这段代码就是语法正确、资源消耗不是非常大的基于vgg的迁移学习算法。那么基于此作一些实验
修改了一下,添加更多内容,主要是数据显示这块import numpy as np
from keras.datasets
import mnist
import gc
from keras.models
import Sequential, Model
from keras.layers
import Input, Dense, Dropout, Flatten
from keras.layers.convolutional
import Conv2D, MaxPooling2D
from keras.applications.vgg16
import VGG16
from keras.optimizers
import SGD
import matplotlib.pyplot as plt
import
os
import cv2
import h5py as h5py
import numpy as np
def tran_y(y)
:
y_ohe
= np.zeros(
10)
y_ohe[y]
=
1
return y_ohe
# 如果硬件配置较高,比如主机具备32GB以上内存,GPU具备8GB以上显存,可以适当增大这个值。VGG要求至少48像素
ishape
=
48
(X_train, y_train), (X_test, y_test)
= mnist.load_data()
X_train
= [cv2.cvtColor(cv2.resize(i, (ishape, ishape)), cv2.COLOR_GRAY2BGR)
for i
in X_train]
X_train
= np.concatenate([arr[np.newaxis]
for arr
in X_train]).astype(
'float32')
X_train
/=
255.
0
X_test
= [cv2.cvtColor(cv2.resize(i, (ishape, ishape)), cv2.COLOR_GRAY2BGR)
for i
in X_test]
X_test
= np.concatenate([arr[np.newaxis]
for arr
in X_test]).astype(
'float32')
X_test
/=
255.
0
y_train_ohe
= np.
array([tran_y(y_train)
for i
in
range(
len(y_train))])
y_test_ohe
= np.
array([tran_y(y_test)
for i
in
range(
len(y_test))])
y_train_ohe
= y_train_ohe.astype(
'float32')
y_test_ohe
= y_test_ohe.astype(
'float32')
model_vgg
= VGG16(include_top
=
False, weights
=
'imagenet', input_shape
= (ishape, ishape,
3))
for layer
in model_vgg.layers
:
layer.trainable
=
False
model
= Flatten()(model_vgg.output)
model
= Dense(
4096, activation
=
'relu', name
=
'fc1')(model)
model
= Dense(
4096, activation
=
'relu', name
=
'fc2')(model)
model
= Dropout(
0.
5)(model)
model
= Dense(
10, activation
=
'softmax', name
=
'prediction')(model)
model_vgg_mnist_pretrain
= Model(model_vgg.
input, model, name
=
'vgg16_pretrain')
model_vgg_mnist_pretrain.summary()
sgd
= SGD(lr
=
0.
05, decay
=
1e
-
5)
model_vgg_mnist_pretrain.
compile(loss
=
'categorical_crossentropy', optimizer
= sgd, metrics
= [
'accuracy'])
log
= model_vgg_mnist_pretrain.fit(X_train, y_train_ohe, validation_data
= (X_test, y_test_ohe), epochs
=
10, batch_size
=
64)
score
= model_vgg_mnist_pretrain.evaluate(x_test, y_test, verbose
=
0)
print(
'Test loss:', score[
0])
print(
'Test accuracy:', score[
1])
plt.figure(
'acc')
plt.subplot(
2,
1,
1)
plt.plot(log.history[
'acc'],
'r--',label
=
'Training Accuracy')
plt.plot(log.history[
'val_acc'],
'r-',label
=
'Validation Accuracy')
plt.legend(loc
=
'best')
plt.xlabel(
'Epochs')
plt.axis([
0, epochs,
0.
9,
1])
plt.figure(
'loss')
plt.subplot(
2,
1,
2)
plt.plot(log.history[
'loss'],
'b--',label
=
'Training Loss')
plt.plot(log.history[
'val_loss'],
'b-',label
=
'Validation Loss')
plt.legend(loc
=
'best')
plt.xlabel(
'Epochs')
plt.axis([
0, epochs,
0,
1])
plt.show()
os.system(
"pause")
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_4 (InputLayer) (None, 48, 48, 3) 0
_________________________________________________________________
block1_conv1 (Conv2D) (None, 48, 48, 64) 1792
_________________________________________________________________
block1_conv2 (Conv2D) (None, 48, 48, 64) 36928
_________________________________________________________________
block1_pool (MaxPooling2D) (None, 24, 24, 64) 0
_________________________________________________________________
block2_conv1 (Conv2D) (None, 24, 24, 128) 73856
_________________________________________________________________
block2_conv2 (Conv2D) (None, 24, 24, 128) 147584
_________________________________________________________________
block2_pool (MaxPooling2D) (None, 12, 12, 128) 0
_________________________________________________________________
block3_conv1 (Conv2D) (None, 12, 12, 256) 295168
_________________________________________________________________
block3_conv2 (Conv2D) (None, 12, 12, 256) 590080
_________________________________________________________________
block3_conv3 (Conv2D) (None, 12, 12, 256) 590080
_________________________________________________________________
block3_pool (MaxPooling2D) (None, 6, 6, 256) 0
_________________________________________________________________
block4_conv1 (Conv2D) (None, 6, 6, 512) 1180160
_________________________________________________________________
block4_conv2 (Conv2D) (None, 6, 6, 512) 2359808
_________________________________________________________________
block4_conv3 (Conv2D) (None, 6, 6, 512) 2359808
_________________________________________________________________
block4_pool (MaxPooling2D) (None, 3, 3, 512) 0
_________________________________________________________________
block5_conv1 (Conv2D) (None, 3, 3, 512) 2359808
_________________________________________________________________
block5_conv2 (Conv2D) (None, 3, 3, 512) 2359808
_________________________________________________________________
block5_conv3 (Conv2D) (None, 3, 3, 512) 2359808
_________________________________________________________________
block5_pool (MaxPooling2D) (None, 1, 1, 512) 0
_________________________________________________________________
flatten_4 (Flatten) (None, 512) 0
_________________________________________________________________
fc1 (Dense) (None, 4096) 2101248
_________________________________________________________________
fc2 (Dense) (None, 4096) 16781312
_________________________________________________________________
dropout_4 (Dropout) (None, 4096) 0
_________________________________________________________________
prediction (Dense) (None, 10) 40970
=================================================================
Total params: 33,638,218
Trainable params: 18,923,530
Non-trainable params: 14,714,688
_________________________________________________________________
Train on 60000 samples, validate on 10000 samples
Epoch 1/10
1536/60000 [..............................] - ETA: 1:13 - loss: 1.9791 - acc: 0.3385
60000/60000 [==============================] - 68s 1ms/step - loss: 0.5406 - acc: 0.8242 - val_loss: 0.2122 - val_acc: 0.9382
Epoch 2/10
6592/60000 [==>...........................] - ETA: 53s - loss: 0.2649 - acc: 0.9122
60000/60000 [==============================] - 68s 1ms/step - loss: 0.2423 - acc: 0.9212 - val_loss: 0.2126 - val_acc: 0.9312
Epoch 3/10
8320/60000 [===>..........................] - ETA: 51s - loss: 0.2082 - acc: 0.9284
60000/60000 [==============================] - 67s 1ms/step - loss: 0.1869 - acc: 0.9394 - val_loss: 0.2757 - val_acc: 0.9060
Epoch 4/10
9024/60000 [===>..........................] - ETA: 51s - loss: 0.1641 - acc: 0.9469
60000/60000 [==============================] - 68s 1ms/step - loss: 0.1569 - acc: 0.9492 - val_loss: 0.1587 - val_acc: 0.9452
Epoch 5/10
9280/60000 [===>..........................] - ETA: 50s - loss: 0.1463 - acc: 0.9547
60000/60000 [==============================] - 67s 1ms/step - loss: 0.1411 - acc: 0.9547 - val_loss: 0.1826 - val_acc: 0.9428
Epoch 6/10
9408/60000 [===>..........................] - ETA: 49s - loss: 0.1309 - acc: 0.9565
60000/60000 [==============================] - 67s 1ms/step - loss: 0.1270 - acc: 0.9588 - val_loss: 0.1280 - val_acc: 0.9594
Epoch 7/10
9408/60000 [===>..........................] - ETA: 50s - loss: 0.1162 - acc: 0.9631
60000/60000 [==============================] - 67s 1ms/step - loss: 0.1170 - acc: 0.9625 - val_loss: 0.1159 - val_acc: 0.9644
Epoch 8/10
9600/60000 [===>..........................] - ETA: 49s - loss: 0.1126 - acc: 0.9627
60000/60000 [==============================] - 67s 1ms/step - loss: 0.1111 - acc: 0.9635 - val_loss: 0.0949 - val_acc: 0.9678
Epoch 9/10
9728/60000 [===>..........................] - ETA: 49s - loss: 0.0921 - acc: 0.9698
60000/60000 [==============================] - 67s 1ms/step - loss: 0.1030 - acc: 0.9654 - val_loss: 0.1173 - val_acc: 0.9600
Epoch 10/10
9792/60000 [===>..........................] - ETA: 49s - loss: 0.0996 - acc: 0.9689
60000/60000 [==============================] - 67s 1ms/step - loss: 0.1007 - acc: 0.9668 - val_loss: 0.1126 - val_acc: 0.9626
Test loss: 0.11260580219365657
Test accuracy: 0.9626
在实际操作 的过程中,非常注意可能出现。这也证明如果自己配置机器,内存至少要32GB.
|

 |手机版|小黑屋|Java自学者论坛
( 声明:本站文章及资料整理自互联网,用于Java自学者交流学习使用,对资料版权不负任何法律责任,若有侵权请及时联系客服屏蔽删除 )
|手机版|小黑屋|Java自学者论坛
( 声明:本站文章及资料整理自互联网,用于Java自学者交流学习使用,对资料版权不负任何法律责任,若有侵权请及时联系客服屏蔽删除 )




 发表于 2021-9-3 15:22:53
发表于 2021-9-3 15:22:53